Mikio L. Braun柏林工业大学机器学习学博士后,TWIMPACT联合创始人兼首席数据科学家。在其个人博客上简述了主流SPF(Stream Processing Framework)与MapReduce的区别 ―― 并没有查询层。
以下为译文:
当着手实时大数据时,SPF不失为MapReduce很好的替代。取代对数据进行批处理,它们在数据出现时就会进行处理;如果你处理的是事件流,使用SPF显然会比MapReduce来的合理。而类似Storm(Twitter)和S4(Yahoo!)这样的框架,显然更适合扩展类似(流处理)的计算。类似于MapReduce作业,你只要指定小的工作线程,然后这些线程会被自动的监视和部署从而提供稳健的扩展性。
所以开始你会觉得“SPF是基于MapReduce的事件版本”,然而这里存在着显著的差别:在流处理中是没有查询层的(最少在Storm和S4中是没有的)。
查询层,你可以通过指令查询出你想要的结果;然而就流处理来说,意味着指令会一直运行,因为你处理的是一个随时都有新时间加入的事件流。
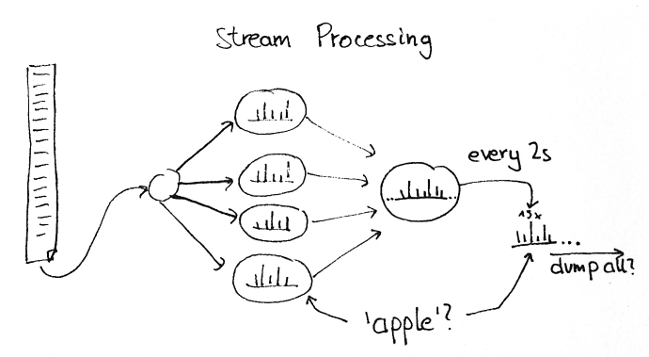
举个例子,着眼随处可见的“单词计数用例”,络绎不绝的导入句子(比如说,Tweet),那么你该如何查询出在一个指定的时间某个指定单词的个数。
答案可能与大部分人所想的不同:没有任何方法可以计算出结果(至少在现有的SPF中)。原因是:每个线程都会被分配数据流的一部分,然而却没有方法去访问这些信息。取而代之的是:结果只能定期的输出,不管是到屏幕或者是持久化储存。

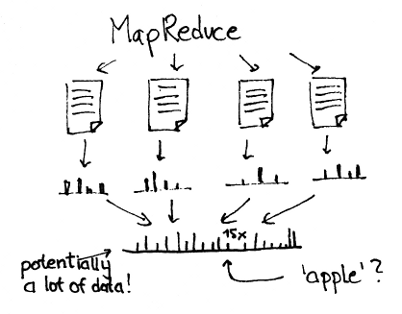
不错,这只是一个比较业余的例子;然而这同样意味着现实中的应用程序,你需要一些数据库后端做结果的储存。取决于你处理的数据量和你所做的聚合程度(或者是不做),这同样意味着你的持久化数据库MySQL可能满足不了流处理集群。
在MapReduce中也同样如此,对数据进行一些定期的修改,而区别在于MapReduce需要做两倍流处理额外后端的储存方案。

Mikio L. Braun认为以下的几个环境适合流处理:
- 针对高频度的事件流
- 每个独立的事件都需要处理高复杂度的分析
- 高聚合度,以至于数据的体积会大量的减少
而在以下的情况可能就不会很适用:
- 每个时间你都需要做许多的持久层修改
- 在分析进行的同时,可能会去做某些结果的查询
显然在IT领域没有通吃的算法及框架,把握自己的程序及数据类型,为其选择合适的分析工具才是王道。
http://www.csdn.net/article/2013-03-05/2814352-spf-mapreduce
Stream Processing has no Query Layer
File under: Machine Room
When it comes to real-time big data, stream processing frameworks are an interesting alternative to MapReduce. Instead of storing and crunching data in batches, they process the data as it comes along, which immediately makes much more sense if you’re dealing with event streams. Frameworks like Twitter’s Storm and Yahoo’s S4allow you to scale such computations. Similar to MapReduce jobs, you specify small worker threads which are then deployed and monitored automatically to provide robust scalability.
So at first you may think “stream processing is basically MapReduce for events”, but there is an important and significant difference: There is no query layer in stream processing (well at least, there isn’t in Storm and S4).
With query layer, I mean the capability to query the results of your computations. For stream processing, in particular, this means while the computations are still running, because you are typically consuming a never-ending stream of new events.
For example, if we consider the ubiquituous word count example, where you pipe in some constant stream of sentences (let’s say, tweets), how can you query the counts for a given word at a given time?
The answer is a bit surprising to most people I’ve talked to: There is no way you can query the result (at least from within the stream processing framework). The information is there, distributed over numerous worker thread who all see and process a part of the stream, but there is no way to access that information. Instead, results have to be periodically output, either to screen or to some persistent storage.
Now these are only toy examples, of course, but it also means that for real-world applications, you need some database backend to store your results. Depending on the amount of data you process and the level of aggregation you do (or don’t do), this also means that your stock MySQL won’t suffice to keep up with your stream processing cluster.
The same can be said of MapReduce jobs which run periodically to update some statistics, but the difference is that MapReduce doubles as the storage solution while you need an additional backend for stream processing.
So I think stream processing is good when:
- you have a high frequency event stream,
- have to do quite complex analyses on each event independently,
- do a lot of aggregation so that there is a huge reduction in data volume.
But it’s not generally applicable when:
- you need to do a lot of persistent updates which each event,
- need to query results while the analysis is still ongoing.
Let me know if I’m wrong. I’d be interested in learning about some real-world experiences with scaling stream processing!
http://blog.mikiobraun.de/2013/03/stream-processing-has-no-query-layer.html